
In today’s data-driven world, recommendations are everywhere – from movies on Netflix to products on Amazon. But how exactly do these systems work? The answer lies in machine learning, specifically a technique called collaborative filtering.This blog post will guide you through building a movie recommendation system using collaborative filtering. We’ll explore the different types of recommendation systems, delve into collaborative filtering, and code a simple Python model to suggest movies you might enjoy.
Different Types of Recommendation Systems
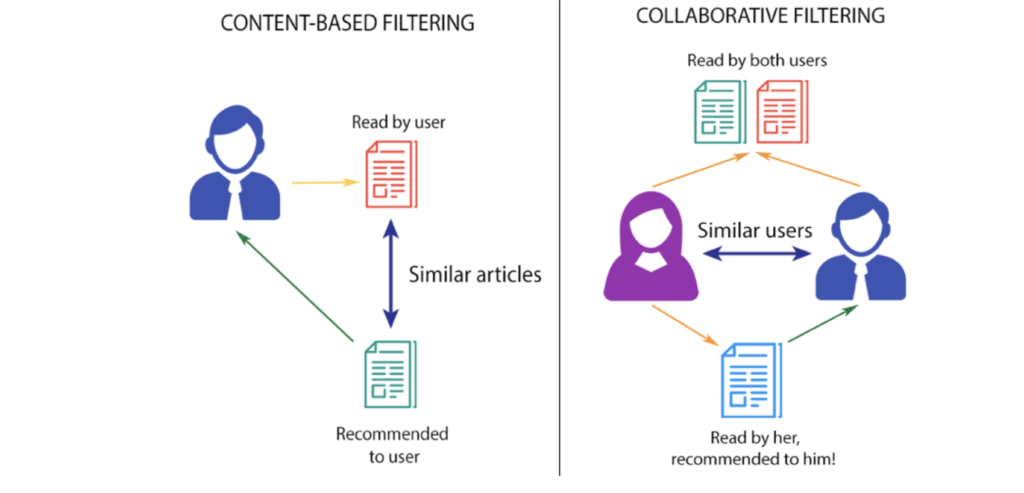
There are two main approaches to building recommendation systems:
Content-based filtering: This method recommends items similar to what you’ve liked in the past. For example, if you enjoyed action movies, the system might suggest other action movies.Collaborative filtering: This method focuses on finding users with similar tastes and recommending items they’ve enjoyed. It doesn’t consider the item’s features itself.
Collaborative filtering offers a wider range of recommendations, introducing you to hidden gems you might not have discovered on your own.
Collaborative Filtering in Action

Here’s how collaborative filtering works:
User-Item Matrix: We create a matrix where users are listed on one side and movies on the other. Each cell represents a user’s rating for a particular movie.Finding Similar Users: The system analyzes the matrix to identify users with similar rating patterns. Imagine users who both loved the same movies – they’re likely to enjoy similar films in the future.Recommendations Based on Similarities: Based on these user similarities, the system recommends movies enjoyed by similar users but haven’t been rated by you yet.
Flowchart for Collaborative Filtering:
+--------------------+
| Start |
+--------------------+
|
v
+--------------------+
| Build User-Item |
| Matrix |
+--------------------+
|
v
+--------------------+
| Find Similar Users |
+--------------------+
|
v
+--------------------+
| Recommend Based on |
| Similar User Likes |
+--------------------+
|
v
+--------------------+
| End |
+--------------------+
Let’s get our hands dirty with some Python code! We’ll use a movie ratings dataset and a K-Nearest Neighbors (KNN) algorithm to build a simple recommender system.1. Data Preparation:We’ll use a publicly available movie ratings dataset containing user IDs, movie IDs, and ratings. We’ll then transform this data into a user-item matrix using Pandas.
import pandas as pd
# Load the dataset
ratings_df = pd.read_csv("ratings.csv")
# Create a user-item matrix
user_item_matrix = ratings_df.pivot_table(index="userId", columns="movieId", values="rating")
user_item_matrix.fillna(0, inplace=True) # Impute missing values with 0
2. Building the KNN Model:KNN is a machine learning algorithm that finds the closest neighbors (most similar users) based on their rating patterns. We’ll define a KNN model using cosine similarity as the distance metric.
from sklearn.neighbors import NearestNeighbors
# Define KNN model
knn_model = NearestNeighbors(metric="cosine", algorithm="brute")
# Fit the model on the user-item matrix
knn_model.fit(user_item_matrix)
3. Recommendation Function:We’ll create a function that takes a movie title as input and uses the KNN model to recommend similar movies. The function will find the closest neighbors (users with similar taste) and recommend movies they’ve enjoyed but you haven’t rated yet.
def recommend_movies(movie_title, user_item_matrix, knn_model, n_recs=10):
"""
Recommends movies based on a given movie title.
Args:
movie_title: Title of the movie to use for recommendations.
user_item_matrix: User-item rating matrix.
knn_model: KNN model trained on the user-item matrix.
n_recs: Number of recommendations to return (default: 10).
Returns:
A Pandas DataFrame containing recommended movies with titles and distances.
"""
# Get movie ID from movie title
movie_id = user_item_matrix.columns.get_loc(movie_title)
# Find nearest neighbors based on movie IDPython
# Get movie titles and distances for nearest neighbors
movie_idx = indices.squeeze().tolist()
movie_dist = distances.squeeze().tolist()
movie_neighbor_df = pd.DataFrame({'movieId': movie_idx, 'distance': movie_dist})
movie_neighbor_df = movie_neighbor_df.merge(user_item_matrix[[movie_title]], on='movieId')
movie_neighbor_df.drop('movieId', axis=1, inplace=True)
movie_neighbor_df.rename(columns={movie_title: 'Rating'}, inplace=True)
# Filter movies not yet rated by the user
user_rated_movies = user_item_matrix.loc[user_item_matrix[movie_title].idxmax()]
recommended_movies = movie_neighbor_df[~movie_neighbor_df['Rating'].isin(user_rated_movies)]
# Sort movies based on distance (nearest neighbors first)
recommended_movies = recommended_movies.sort_values(by='distance')
# Return top n recommendations
return recommended_movies.head(n_recs)
4. Getting Recommendations:
Finally, we’ll call the recommendation function with a movie title (e.g., “The Godfather”) and get a list of recommended movies based on users who enjoyed that film.
# Example usage
movie_recs = recommend_movies("The Godfather", user_item_matrix, knn_model)
print(movie_recs)
This code snippet will print a Pandas DataFrame containing the titles and distances of the top 10 recommended movies for “The Godfather”.
Advantages and Limitations of Collaborative Filtering

Advantages:
- Personalized Recommendations: Tailored suggestions based on user behavior.
- Diverse Content Discovery: Recommends a wider range of movies you might not have found on your own.
- Community Wisdom: Leverages collective preferences for potentially more accurate recommendations.
- Dynamic Adaptation: The model continuously updates with user interactions, keeping recommendations relevant.
Limitations:
- Cold Start Problem: Difficulty recommending new movies or users with limited data.
- Popularity Bias: Popular movies tend to get recommended more often, overshadowing lesser-known gems.
- Scalability Issues: Managing large datasets can be computationally expensive.
Conclusion
Collaborative filtering is a powerful tool for building personalized recommendation systems. While it has limitations, the ability to suggest relevant and diverse content makes it a valuable asset in the machine learning landscape. As technology evolves, these systems will become even more sophisticated, shaping our digital experiences in exciting ways.
Ready to build your own movie recommender system? Grab your Python code and start exploring!
Note: This blog post provides a high-level overview of the concepts. The actual code implementation might involve additional libraries and functionalities.